(발번역) 딥러닝의 한계들
원문 : https://blog.keras.io/the-limitations-of-deep-learning.html
저자인 François Chollet의 허락을 받고 번역했음을 알려드립니다.
이 글은 Deep Learning with Python Chapter 9의 Section 2의 내용을 각색하였다. 딥러닝의 현재 한계와 미래에 대한 2개의 시리즈 글 중에 하나이다.
이 글은 딥러닝으로 의미있는 경험을 해보고 사전 지식이 어느정도 있는 사람들에게 맞춰져 있다.
딥러닝:기하학적 관점(the geometric view)
딥러닝 관련해서 가장 놀라운 점은 그것이 굉장히 간단하다는 것이다. 10년전, 어느 누구도 우리는 기계 인식 분야에서 경사하강법으로 트레이닝된 간단한 파라미터 모델을 사용해서 이러한 놀라운 결과를 쌓을 것이라고 기대하지 않았다. 현재, 당신이 필요로하는 모든 것들이 충분히 많은 예제에서 경사하강법으로 트레이닝된 충분히 큰 파라미터 모델들이 나오고 있다. 파인먼(Feynman, 미국 물리학자)이 이 우주에 대해 한번 말한적이 있다. “복잡한게 아니라, 단지 많은 것 뿐이다”.
딥러닝에서 모든것은 벡터(vector)이다. 모든 것들이 기하학적인 공간의 한 점인 것처럼. 입력 모델(텍스트, 이미지 등)과 타겟들은 먼저 “벡터화”되어, 즉 초기 입력 벡터 공간 및 타겟 벡터 공간으로 바뀐다. 딥러닝 모델의 각 계층(layer)은 이를 통과하는 데이터들에 대해 간단한 기하학적 변환(geometirc transformation)을 수행한다. 그와 함께 모델 계층들의 체인은 하나의 매우 복잡한 기하학적 변환을 형성하며 일련의 단순한 변환으로 나뉜다. 이 복잡한 변환은 한번에 한 지점씩 입력 공간이 타겟 공간으로 매핑되도록 한다. 이 변환은 모델이 현재 어떻게 수행되는지에 따라 반복적으로 갱신되어지는 계층들의 가중치로 매개변수화된다. 기하학적 변환의 핵심 특징은 경사하강법을 통해 매개 변수들을 학습할 수 있어야 한다는 점에서 차별화되어야 한다. 즉, 입력부터 출력까지의 기하학적 형태가 매끄럽고 연속적이어야 하는 중요한 제약이 있다.
입력 데이터에 대한 복잡한 기하학적 변형을 적용하는 전체 프로세스는 사람들이 페이퍼볼(paper ball, 종이를 구겨서 만든 공)을 펴는 모습을 상상하듯이 3차원으로 시각화 되어질 수 있다(구겨진 페이퍼볼은 모델이 시작될때 사용되는 다양한 입력 데이터라고 볼 수 있다). 페이퍼볼을 가지고 사람들이 조작하는 각 움직임들은 한 계층에 의해 수행되는 단순한 기하학적인 변환과 유사하다. 완전히 펴지게 하는 움직임들은 전체 모델의 복잡한 변환이다. 딥러닝 모델들은 복잡한 수많은 고차원 데이터를 펴기 위한 수학적 기계이다.
이것이 딥러닝의 마술이다. 의미를 벡터로 변환하고, 기하 공간으로 변환한 다음 한 공간에서 다른 공간으로 매핑하는 복잡한 기학학적인 변환들을 점진적으로 학습한다. 당신이 필요한 것들은 원본 데이터 안에서 발견된 관계들의 모든 범위를 캡쳐하기 위한 충분히 높은 차원의 공간들 뿐이다.
딥러닝의 한계들
이 간단한 전략으로 구현할 수 있는 어플리케이션의 공간은 거의 무한하다. 하지만 사람이 주석을 단 방대한 양의 데이터가 있음에도 현재의 딥러닝 기술로는 훨씬 더 많은 어플리케이션들이 도달하지 못하고 있다. 예를 들어, 제품 매니저가 영문으로 작성한 소프트웨어의 특징과 해당 요구사항을 충족하기 위해 엔지니어팀이 개발한 소스코드를 포함하여 수십(혹은 수백)만개의 데이터셋을 모을 수 있다고 해보자. 이러한 데이터들을 통해 제품 설명서를 읽고 적절한 코드 베이스를 생성하기 위해 딥러닝 모델을 트레이닝 할 수 없다. 이것은 수많은 예중에 단지 하나일 뿐이다. 일반적으로 장기적인 계획을 세우거나 알고리즘 같은 데이터 조작에 대해 추론을 요구하는 것들(프로그래밍 또는 과학적 방법 적용)은 수많은 데이터를 쏟아부어도 딥러닝 모델로 도달할 수 없다. 딥뉴럴넷으로 소팅 알고리즘을 학습하는 것조차 엄청나게 어려운 일이다.
이것은 딥러닝 모델이 “단지” 하나의 벡터 공간을 다른 것으로 매핑하는 단순하고 연속적인 기하학적 변형들의 연결이기 때문이다. X에서 Y로 학습 가능한 연속적인 변형과 학습 데이터로 사용되기 위한 X,Y의 고밀도 샘플링의 유효성을 가정하고 하나의 데이터 다양체(manifold) X를 다른 다양체 Y로 매핑하는 것이다. 따라서 딥러닝 모델은 프로그램의 일종으로 해석될 수 있지만, 대부분의 프로그램들은 딥러닝 모델로 표현될 수 없다(대부분의 태스크에서 실제 해당되는 것들은 없다). 그것을 해결할 만한 크기의 딥뉴럴넷이 거기에 하나라도 있다 해도 학습할 수 있는 것은 아닐 것이다. 기하학적인 변형에 상응하는 것은 너무나 복잡하거나 그것을 학습할 수 있는 적절한 데이터가 없을 것이다.
더 많은 계층을 쌓고 더 많은 학습 데이터를 사용하여 현재 딥러닝 기술을 키우는 것은 단지 이러한 이슈들의 일부만 표면적으로 완화시킬 수 있다. 딥러닝 모델들이 표현할 수 있는 것이 꽤 제한적이고, 학습하고자 하는 대부분의 프로그램들은 데이터 다양체의 연속적인 기하학적 모핑(morphing)으로 표현할 수 없다는 근본적인 문제를 해결하지 못할 것이다.
머신러닝 모델을 의인화하는 위험성
현대의 인공지능에 대한 하나의 실질적인 위험은 딥러닝 모델이 하고 있는 것을 잘못 해석하는 것과 그 능력이 과대평가되었다는 것이다. 인간 마음의 근본적인 특징은 우리 주변의 것들에 대한 의도와 신념, 지식을 투영하려는 우리의 “마음 이론(theory of mind)”이다. 바위에 웃는 얼굴을 그리는 것은 갑자기 마음속으로 “행복”하게 만들어준다. 딥러닝에 적용하면, 이것은 우리가 그림을 설명하기 위한 캡션을 만들어내기 위해 모델을 성공적으로 훈련시킬 수 있음을 의미하는데, 예를 들어 우리는 모델이 그림의 내용을 “이해”하고, 반대로 캡션이 이미지를 만들어낸다는 믿음으로 이끈다. 그리고 나서 훈련 데이터에 있는 이미지와 약간의 차이로 인해 모델이 완전히 우스꽝 스러운 캡션을 만들기 시작하면 우리는 매우 놀라게 된다.

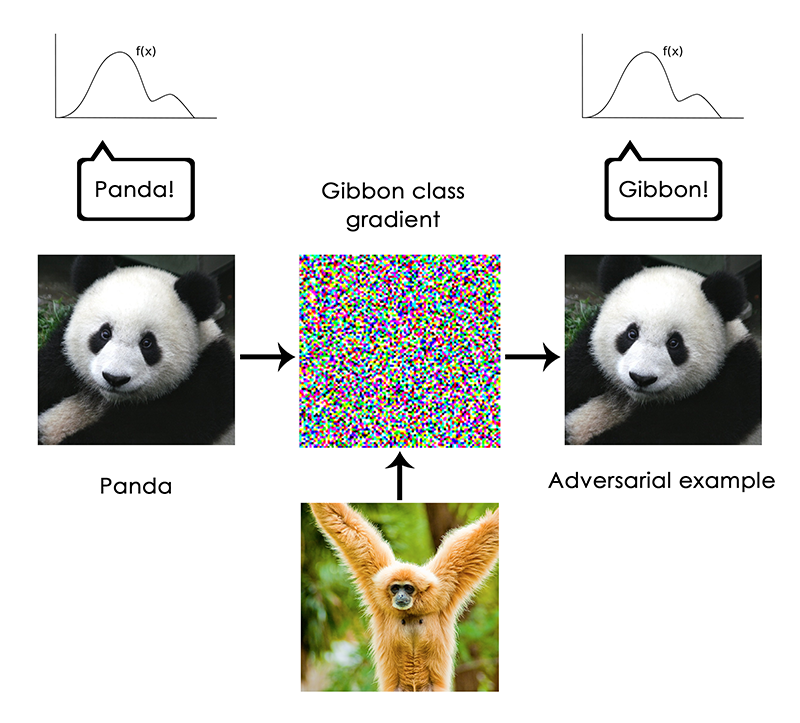
특히, 이것은 “adversarial examples”에 의해 강조된다. 이 예제는 모델을 속여 잘못 분류하도록 고안된 딥러닝 네트워크의 입력 샘플이다. 우리는 일부 컨브넷(convnet) 필터의 활성화를 최대화 하는 입력을 생성하기 위해 입력 공간에서 경사상승법(gradient ascent)을 수행할 수 있음을 이미 알고있다. 예를 들면, 이것은 5장(of Deep Learning with Python)에서 소개한 필터 시각화 기술과 8장의 딥드림(Deep Dream) 알고리즘의 기초가 되었다. 마찬가지로 경사상승법을 통해 주어진 분류로 예측을 최대화하기 위한 약간의 이미지 변경도 할 수 있다. 판다의 사진이 주어지고 거기에 “긴팔원숭이(gibbon)” 경사(gradient)를 추가하면, 우리는 판다를 긴팔원숭이로 분류하는 뉴럴넷을 얻을 수 있다. 이것은 모델들의 불안정함과 인간이 인식하는 것과 모델이 만들어내는 입-출력 매핑사이의 깊은 차이의 증거가 된다.
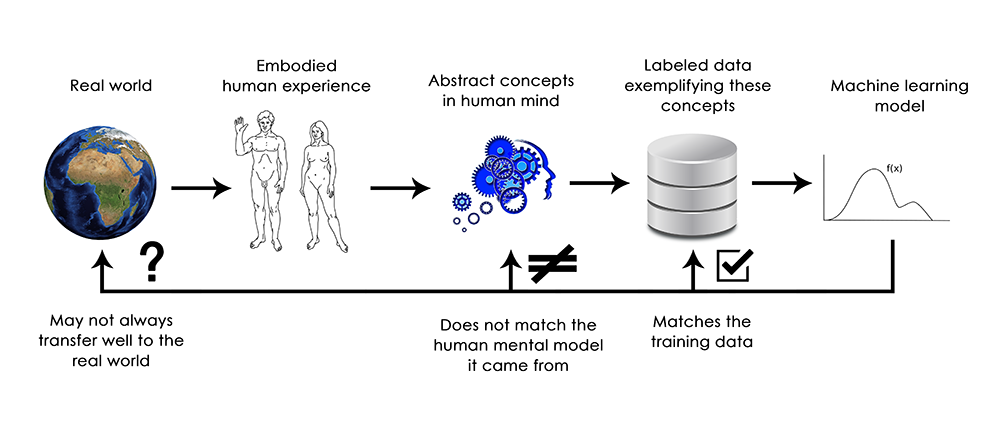
요약하면, 딥러닝 모델은 적어도 인간 감각 뿐만 아니라, 그 입력에 대한 어떤 이해도 없다. 우리가 가지고 있는 이미지, 소리, 언어에 대한 이해는 (땅에 사는 생명체)인간으로서의 감각 운동 경험에서 구체화된다. 머신러닝모델은 이러한 경험의 접근을 가지고 있지 않으며 그래서 인간과 관련된 방법으로 입력에 대한 “이해”를 할 수 없다. 모델에 넣는 수 많은 트레이닝 예제에 주석을 달아서 모델에 적용하면 특정 예제에서 데이터를 인간의 개념으로 매핑하는 기하학적 변환을 배우게 된다. 그러나 이러한 매핑은 임베디드 에이전트로서 우리의 경험으로 부터 나온 우리 마음속에 있는 근본 원리의 간단한 스케치에 불과하다(이것은 거울 속의 희미한 이미지와 같다).
머신러닝을 전문으로 하는 사람으로서, 항상 이것에 유념하고 뉴럴넷 자신이 수행하는 작업을 이해하고 있다는 믿는 함정에 결코 빠지지 말아야 한다. 뉴럴넷은 적어도 우리가 이해하는 방식으로는 하지 않는다. 우리가 가르치고 싶었던 것보다 훨씬 더 좁고 다른 방식으로 트레이닝되었다(단순히 트레이닝 입력을 트레이닝 타겟으로 매핑하는 것이다). 트레이닝 데이터에서 벗어나는 것을 보여주면 뉴럴넷은 가장 터무니 없는 방법으로 무너질 것이다.
지역적 일반화 vs 극단적 일반화(Local generalization versus extreme generalization)
거기에는 입력에서 출력까지 딥러닝 모델이 하는것과 같은 기본적인 기하학 모핑과 인간이 생각하고 배우는 방법의 기본적인 차이만 있는 것처럼 보인다. 인간이 명백한 트레이닝 예를 제시하는 것 대신에 구체화된 경험으로 부터 스스로 배우는 것은 아니다. 다른 학습과정의 한켠에서 기본 표현의 본질에는 근본적인 차이가 있다.
인간은 신경망이나 곤충 처럼 즉각적인 반응에 즉각적인 자극을 부여하는 것 이상을 할 수 있다. 인간은 자신과 다른 사람들의 현재 상태에 대한 복잡하고 추상적 모델들이 유지되며, 다른 가능한 미래를 예측하거나 장기 계획을 수행하기 위한 모델을 사용할 수 있다. 인간은 결코 경험하지 못한 것들(말이 청바지를 입은 것을 그리는 것 또는 로또에 당첨되었을때 무엇을 할것인지에 대한 상상)을 표현하기 위해 알려진 개념들을 서로 합칠 수 있다. 이것은 가설을 다루고 우리가 직접 경험할 수 있는 것 이상으로 정신 모형 공간을 확장할 수 있는 능력이다. 한마디로 말해서, 추상(관념)과 추론을 수행하는 것은 인간 인지의 틀림없는 정의된 특징이다. 이것을 “극단적 일반화(extreme generalization)”라고 부른다(아주 작은 데이터 혹은 새로운 데이터 없이 전에 경험하지 못한 참신한 것에 적응할 수 있는 능력).
신경망이 하는 것과는 매우 대조적으로 대신하는 것을 “지역적 일반화(local generalization)”라고 부른다. 새로운 입력이 트레이닝때 보았던 것과 조금이라도 다르면 신경망에 의해 수행된 입력에서 출력으로의 매핑은 의미를 만드는 것을 빨리 멈추게 한다. 예를들어, 달 착률을 위한 로켓을 만들기 위해 적절한 발사(lauch) 변수를 학습하는 문제를 생각해보자. 당신이 이것을 위해 지도학습 또는 강화학습을 트레이닝해서 신경망을 사용한다면 수천 수백만번의 발사 시험을 해야만 할 것이다. 즉, 당신은 입력 공간에서 출력 공간으로의 신뢰할 수 있는 매핑을 학습하기 위해 고밀도로 샘플링 해야만 한다. 그에 반해서, 인간은 물리적 모델(로켓 과학)을 제시하기 위해 관념(추상)의 힘을 사용할 수 있고, 한번 혹은 적은 시도로 달착률 로켓을 만드는 정밀한 방법을 이끌어 낼 수 있다. 유사하게 당신이 신체를 제어하는 신경망을 만들거나 자동차에 부딪히지 않고 도시를 안전하게 다닐 수 있게 학습하길 원한다면, 차와 위험을 추측하고 회피 행동을 개발할 때 까지 그 신경망은 다양한 환경에서 수천 번 죽어야한다. 새로운 도시에 떨궈졌을때, 그 신경망은 알아야할 모든 것들을 다시 배워야한다. 반면에 인간은 한번도 죽지않고 안전하게 행동하는 것을 배울 수 있다. 가상 상황에 대한 추상 모델링의 힘에 감사해야 한다.
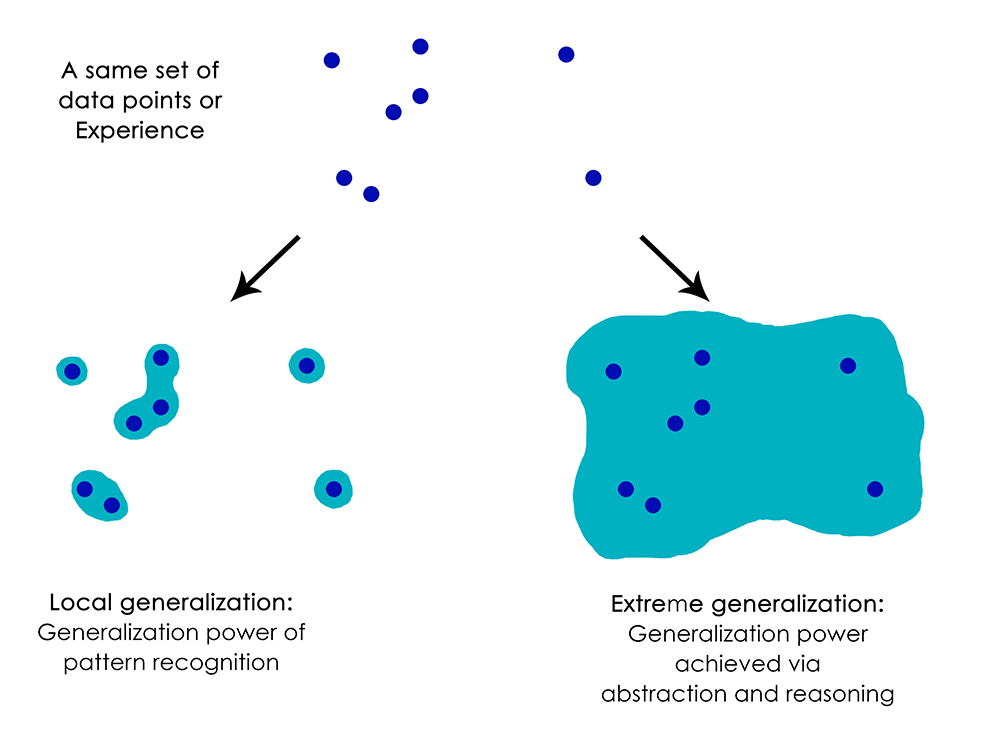
요약하면, 기계인식에 대한 우리의 진전에도 불구하고 우리는 여전히 인간 수준의 AI와는 거리가 꽤 있다. 우리가 만든 모델들은 과거의 데이터와 매우 가깝게 유지되어야 하는 새로운 상황에 적응하는 단지 지역적 일반화(local generalization)만 수행한다. 반면에 인간의 인식은 근본적으로 새로운 상황에 빨리 적응하고, 매우 장기적인 미래의 계획을 세울 수 있는 극단적 일반화(extreme generalization)의 능력을 가지고 있다.
유념해야할 점
여기엔 당신이 기억해야만 하는 것이 있다. 인간이 라벨링한 큰 양의 데이터를 연속적인 기하학적 변환을 사용하여 공간X를 공간Y로 매핑하는 정도 까지가 단지 딥러닝의 성공이다. 이것을 잘 수행하는 것은 근본적으로 모든 산업의 게임 체인저(game-changer)겠지만, 여전히 인간 수준의 AI와는 꽤 거리가 멀다.
이러한 한계들을 끌어올리고 인간의 두뇌와 경쟁을 시작하기 위해서는 단순한 입출력 매핑에서 추론과 추상(관념)으로 이동해야 한다. 여러 상황과 개념의 추상 모델링을 위한 적절한 기질은 컴퓨터 프로그램이의 기질이다. 우리는 전에 머신러닝 모델은 “학습가능한 프로그램(learnable programs)”과 같이 정의되어질 수 있다고 말한적이 있다. 현재 우리는 매우 좁고 모든 가능한 프로그램의 특정한 부분에 속해있는 프로그램만 배울 수 있다. 그러나 우리가 모듈화되고 재사용 가능한 방식으로 어떤 프로그램을 배울 수 있다면 어떨까? 다음 글에서 그 길이 어떻게 보이는지 보도록 하자.
여기서 두번째 파트(딥러닝의 미래)를 읽을 수 있다.
@fchollet, 2017년 5월