(발번역) 추천 시스템 알고리즘(근래 주로 사용되는 추천 엔진과 동작 방식)
원문 : https://blog.statsbot.co/recommendation-system-algorithms-ba67f39ac9a3
오늘날, 많은 회사들이 굉장히 의미있는 추천과 이익 증대를 위해 빅데이터를 사용한다. 여러가지 추천 알고리즘 중에 데이터 사이언티스트들은 비지니스의 제약사항과 요건에 따라서 가장 좋은 것을 선택해야만 한다.
이 작업을 단순화하기 위해 Statsbot팀은 주로 사용되는 추천 시스템 알고리즘에 대한 대략적인 내용을 준비했다.
협업 필터링
협업 필터링(Collaborative Filtering, CF)과 그 변형들은 가장 일반적으로 많이 사용되는 추천 알고리즘 중에 하나이다. 초보 데이터 사이언티스트 조차 이 시스템을 사용하여 예를들어 이력서 프로젝트와 같은 개인 영화 추천 시스템을 구축할 수 있다.
우리가 사용자에게 무언가를 추천하려고 할때, 가장 논리적인 방법은 유사한 관심사를 가진 사람들을 찾고, 그들의 행동을 분석하여 사용자에게 동일한 아이템들 추천하는 것이다. 또는 그 사용자들이 이미 구매한 것들을 조사하여 그와 같은 제품들을 추천하는 것이다.
CF에는 두가지 접근 방법이 있다. 사용자 기반의 협업 필터링과 아이템 기반의 협업 필터링이다.
이 추천 엔진 모두 두가지 과정이 있다.
-
데이터베이스에 얼마나 많은 사용자와 아이템들이 주어진 사용자와 아이템들과 유사한지 찾는다.
-
더 유사한 사용자/아이템의 총 가중치를 고려해서, 이 제품을 사용자에게 제공하기 위한 점수를 예측하기 위해 다른 사용자/아이템들을 평가한다.
이 알고리즘에서 ‘가장 유사하다’는 의미는 무엇일까?
우리가 가진 모든 것은 각 사용자별 선호도 벡터(행렬의 행)와 각 상품의 사용자 점수 벡터(행렬의 열)이다.
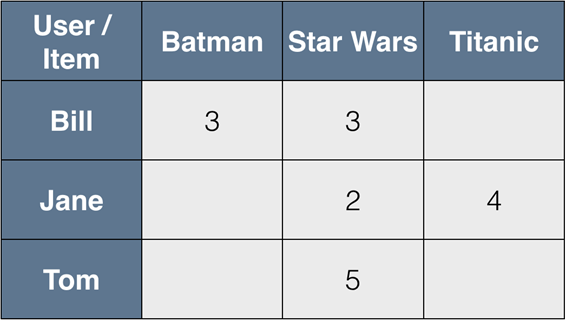
가장 먼저, 두 벡터값을 알고있는 요소들만 남겨두자.
예를 들면, Bill과 Jane을 비교하길 원한다면, Bill은 타이타닉을 관람하지 않았고 Jane은 배트맨을 관람하지 않았다고 말할 수 있고, 스타워즈에 의해서만 그들의 유사도를 측정할 수 있다. 어느 누가 스타워즈를 안볼 수 있단 말인가? ㅎㅎ
유사도를 측정하기 위한 가장 유명한 기술들은 사용자/아이템들 벡터간의 코사인 유사도 측정(cosine similarity) 혹은 상관관계 측정(correlations) 방법이다. 마지막 단계는 테이블의 빈칸들을 채우기 위해 유사도에 따라 가중산술평균(weighted arithmetic mean)을 구하는 것이다.
추천을 위한 행렬 분해
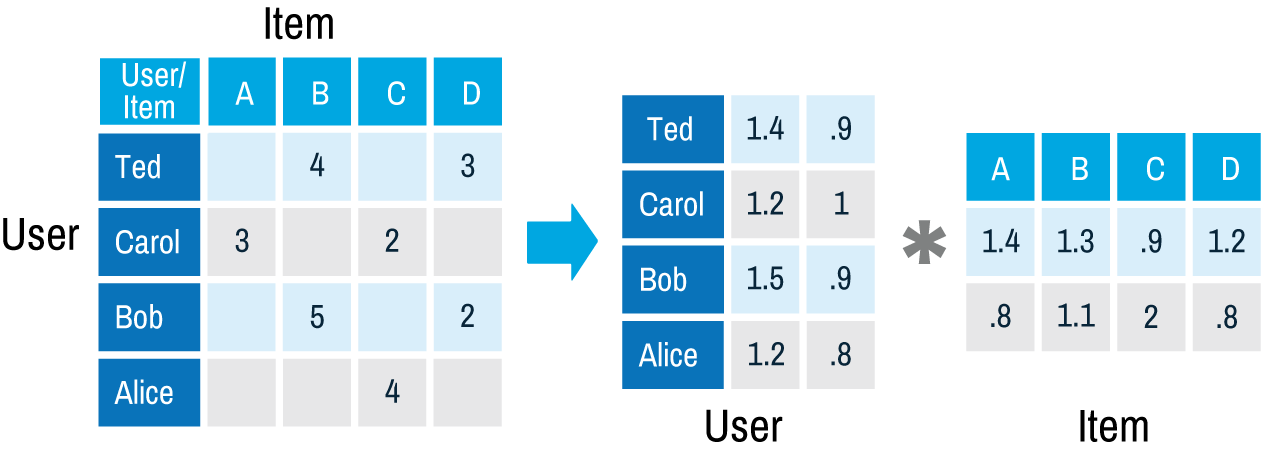
그 다음 관심있는 접근방법은 행렬 분해를 사용하는 것이다. 그것은 매우 우아한 추천 알고리즘이다. 왜냐하면 일반적으로 행렬 분해와 관한 것은 결과 행렬들의 행과 열에 무엇이 남게 되는지 생각하지 않아도 되기 때문이다. 하지만 이 추천 엔진을 사용할때는 u가 i번째 사용자의 관심 벡터이고 v는 j번째 영화의 매개변수 벡터라는 것을 확실히 알아야 한다.
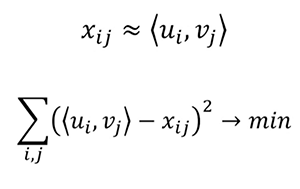
그래서 u와 v의 내적으로 x(i번째 사용자의 j번째 영화에 대한 점수)를 근사치로 계산할 수 있다. 우리는 그렇게 구한 스코어로 벡터를 만들고 점수를 예측하기 위해 그 벡터들을 사용한다.
예를 들어 행렬 분해후, Ted의 벡터(1.4; .9)와 영화 A의 벡터(1.4; .8)를 얻었다면 우리는 단지 (1.4; .9)와 (1.4; .8)의 내적을 구해서 영화 A에 대한 Ted의 점수 2.68을 얻을 수 있다.
클러스터링
이전의 추천 알고리즘들은 꽤 간단하며 소규모 시스템에 적절하다. 지금까지 추천 문제는 지도 기계학습 과제(supervised machine learning task)와 같은 것으로 여겨지고 있다. 이제는 이 문제를 비지도 방식으로 풀어볼 시간이다.
협력 필터링과 행렬 분해가 더 오래 작동되어야 하는 규모있는 추천 시스템을 만든다고 상상해보자. 첫번째 아이디어는 클러스터링일 것이다.
비지니스를 시작할때, 이전 사용자들의 점수가 부족하다면 클러스터링이 가장 좋은 방법이 될 수 있다.
하지만 클러스터링 단독으로는 약간 약하다. 왜냐하면, 실제로 우리가 하는 일이 사용자 그룹을 식별하고 같은 그룹의 사용자들에게는 동일한 아이템들을 추천하기 때문이다. 충분한 데이터가 있는 경우 협업 필터링 알고리즘에서 관련된 이웃들의 선택을 좁히기 위한 첫번째 단계로 사용하는 것이 낫다. 또한 복잡한 추천 시스템의 성능을 향상시킨다.
각 클러스터는 클러스터에 속한 고객들의 선호도 기반하에 일반적인 선호도에 할당될 것이고, 각 클러스터에 있는 고객들은 클러스터 레벨에서 계산된 추천을 받게 될 것이다.
추천을 위한 딥러닝 접근방법
지난 10년간 뉴럴넷트웍은 커다란 도약을 이루었다. 오늘날 폭넓은 어플리케이션에 적용되어 있고 서서히 전통적인 머신러닝 방법들을 대체하고 있다. 딥러닝 방법이 유튜브에 어떻게 사용되어지는 보여주겠다.
의심할 여지 없이, 대규모이고 동적인 말뭉치와 관찰 불가능한 외부의 다양한 요소들이 있는 이러한 서비스를 위한 추천을 만드는 것은 매우 도전적인 과제이다.
“유튜브 추천을 위한 딥뉴럴넷(Deep Neural Networks for YouTube Recommendations)” 연구에 따르면, 유튜브의 추천 시스템 알고리즘은 두가지로 되어있다. 하나는 후보 세대를 위한 것이고 다른 하나는 순위를 위한 것이다. 당신이 시간적 여유가 없다는 가정하에, 이 연구에 대해 빠르게 볼 수 있는 요약을 여기에 남기도록 하겠다.
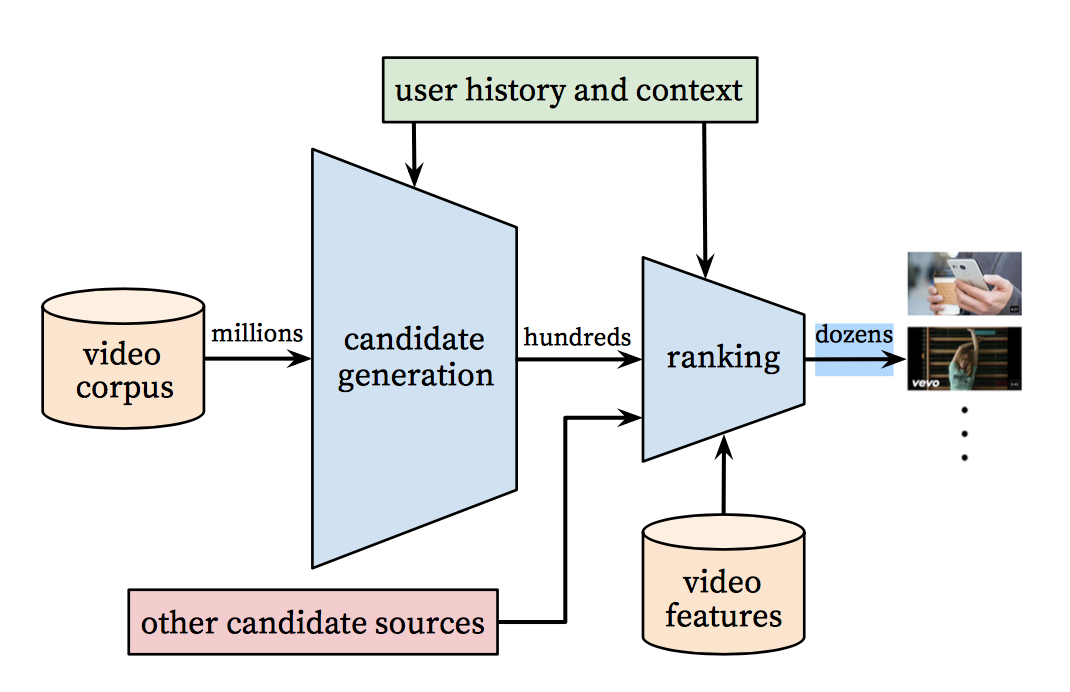
사용자 기록에서 이벤트를 입력으로 가져오는 후보 세대 네트웍은 비디오의 개수를 상당히 줄여주고, 큰 무리에서 가장 관련있는 것들로 그룹을 만들어준다. 그렇게 만들어진 후보군은 그 사용자에게 가장 관련이 있으며, 그 점수를 우리가 예측한다. 이 네트웍의 목적은 단지 협업 필터링을 거친 광범위한 개인화를 제공하는 것이다.
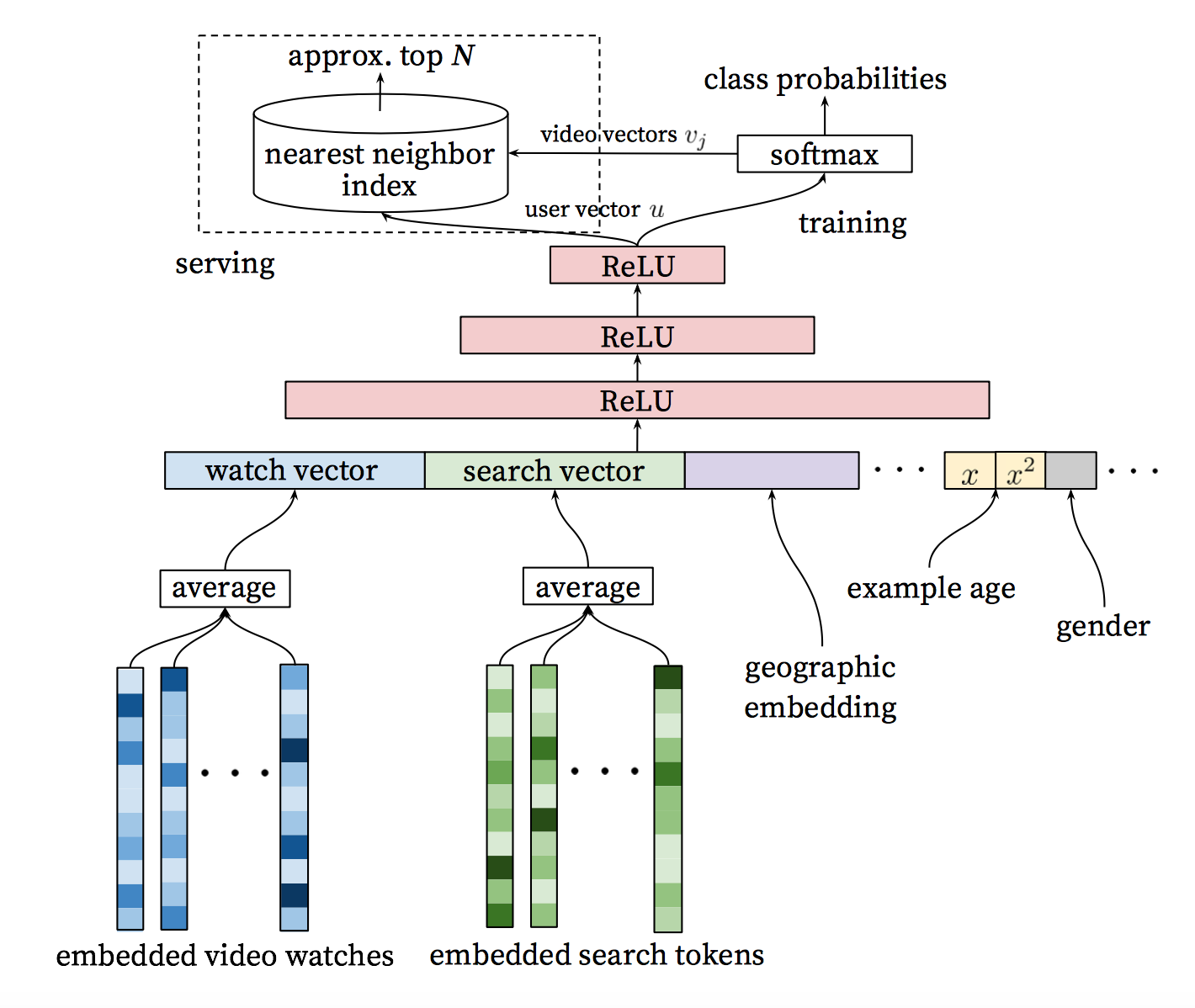
이 단계에서, 우리는 그 사용자와 유사한 좀더 작은 후보군을 추린다. 우리의 목표는 이제 최고의 판단을 할 수 있도록 그 후보군 모두를 신중하게 분석하는 것이다. 이 작업은 랭킹 네트웍이 가장 잘 할 수 있고, 사용자 행동에 대한 정보와 비디오 설명 데이터를 사용하는 훌륭한 목적 함수에 의해 각 비디오에 점수를 부여한다. 가장 높은 점수의 비디오들은 점수에 따라 순위가 매겨지고 사용자에게 보여진다.
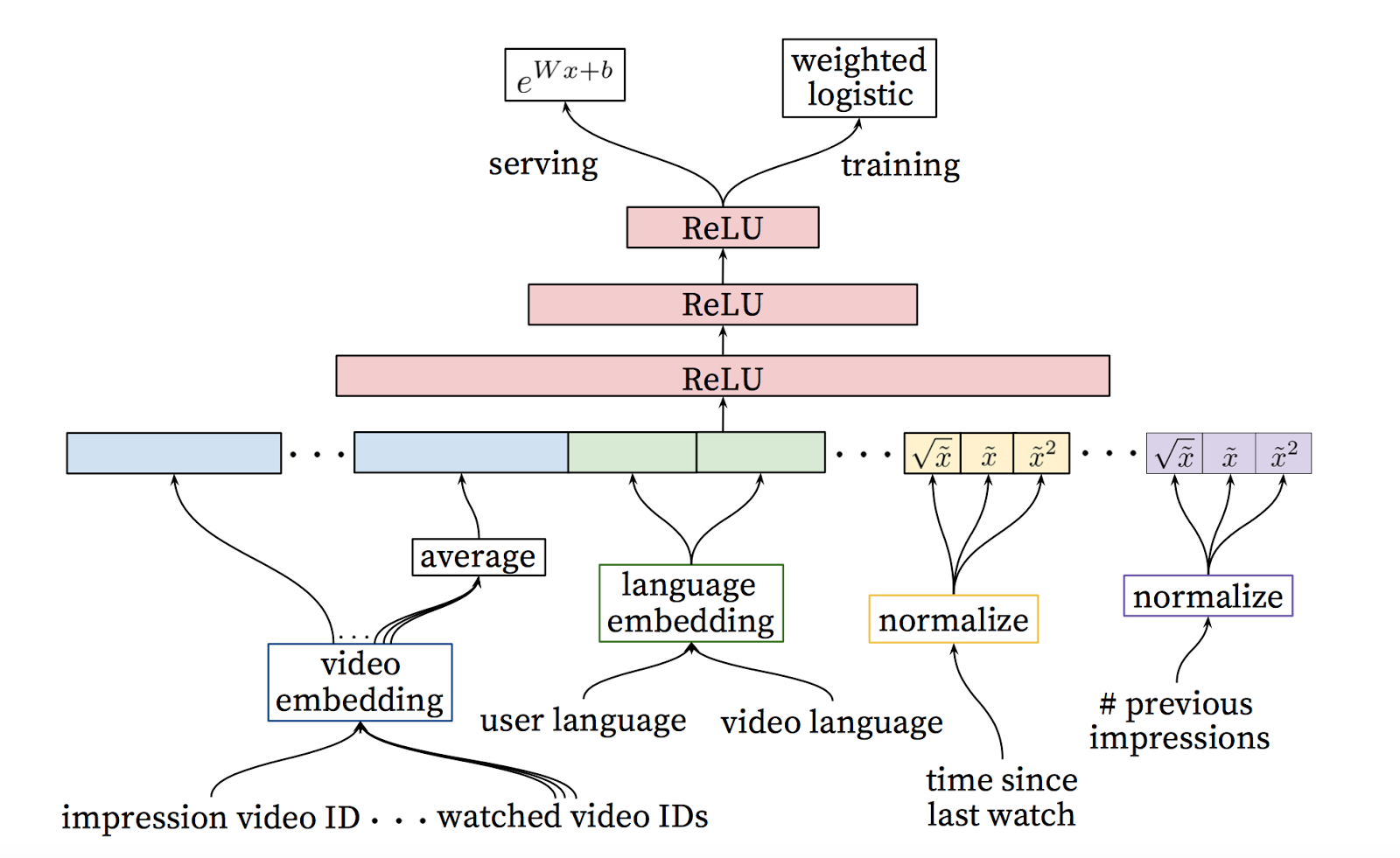
두 단계 접근법을 사용하여 매우 큰 비디오 뭉치로 부터 비디오 추천을 할 수 있으며, 소수의 사용자들에게 개인화를 제공하고 그 사용자들에게 만족을 줄 수 있다. 이 설계는 또한 다른 출처에서 생성된 후보를 서로 혼합할 수 있게 한다.
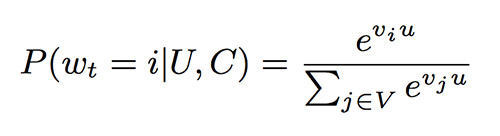
이 추천 작업은 사용자(U)와 컨텍스트(C)를 기반으로 하는 말뭉치로 부터 수백만개의 비디오 클래스(i)에서 주어진 시간 t에 특정 비디오 시청(wt)을 정확하게 분류하는 극단적인 멀티클래스 분류 문제로 제기된다.
당신만의 추천 시스템을 구축하기 전에 알아야할 중요한 사항들
- 당신이 큰 데이터 베이스 가지고 온라인에서 그것을 이용하여 추천 시스템을 만든다면, 가장 좋은 방법은 2개의 하위 문제로 나누는 것이다. 1) 최상위 N개의 후보를 선택하고 2) 그것들의 순위를 매긴다.
- 당신은 모델의 품질 측정을 어떻게 하는가? 표준 품질 측정 항목과 함께 추천 문제를 위한 몇가지 특별한 지표가 있다. Recall@k와 Precision@k 그리고 평균 Recall@k와 평균 Precision@k. 또한 추천 시스템을 위한 측정 항목의 훌륭한 설명을 살펴봐라.
- 당신이 분류 알고리즘을 사용하여 추천 문제를 풀고 있다면, 네거티브 샘플을 생성하는 것을 생각해봐야 한다. 사용자가 추천된 제품을 샀다면, 그것을 포지티브 샘플로 넣거나 다른 것을 네거티브 샘플로 넣어서는 안된다.
- 알고리즘 품질의 온라인 및 오프라인 스코어에 관해 생각하라. 과거 데이터 기반의 트레이닝 모델은 초기 원시적인 시스템으로 이끌 수 있다. 왜냐하면 그 알고리즘은 새로운 동향과 선호들을 알 수 없기 때문이다.